//
Subscribe to the Tabnine newsletter
//
Get news and updates about AI, software development, and more.

We just released a new feature that should significantly reduce the Tabnine memory footprint on your machine if you are using Tabnine with multiple project windows or multiple different IDEs.
Our deep model is trained on millions of open-source projects in various programming languages, providing the magic that is Tabnine.
The deep model can be used through our cloud service or can be downloaded and run locally on your machine. As deep models go, the model itself (with over 355M parameters) can require as much as 1GB of memory on your machine.
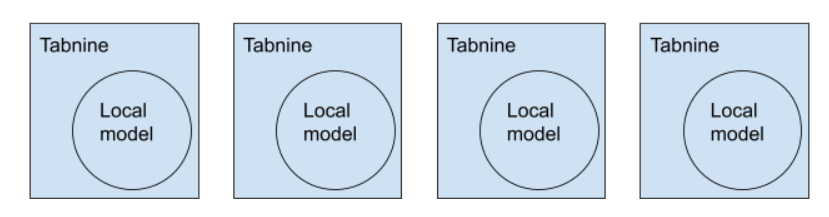
Prior to this release, IDEs such as VScode, which use a separate extension host process for each project, had a separate Tabnine instance for each open project. With many of our users (including ourselves) constantly working with multiple open projects, this often led to massive overall memory consumption by Tabnine.
It became very clear that this is something we needed to fix. Running a single deep model is heavy enough, but loading multiple instances of the same model into memory simply does not make sense.
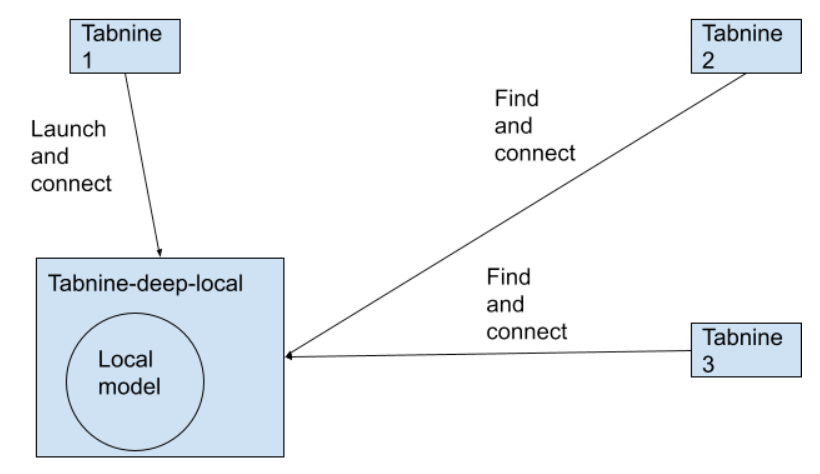
We refactored out the entire module of downloading and evaluating our deep model into its own process, named TabNine-deep-local. This process had a TCP endpoint that the main Tabine binary can communicate with in order to do local model predictions.
Before:
After:
The way there
We transformed the deep local handling module into a “microservice”. This included transforming function calls into message passing, but also getting rid of shared state. One example of a shared state was the model download state object, which was essentially a global object that was used both inside local model handling, but also outside, in the UI, to display the download state to the user.

Once refactoring was done and everything was message passing, it was pretty straightforward to transform this in-memory message passing into a tcp based message passing. The last step was to make sure we only ever had one TabNine-deep-local process running and there was a way for TabNine processes to find it and-reuse it if it was already running, instead of running their own.
Aside from that, there were many other issues that needed to be handled.
Two big ones were:
The auto-update mechanism: Before we only had one binary to download. Now we had two, and plans for other binaries as well (more on that later), so we needed to transform the automatic updates mechanism to download bundles of binaries instead of a single binary.
The watchdog: Tabnine already had a watchdog process that made sure Tabnine did not consume excessive resources. Now it needed to watch multiple processes instead of just one, some of which were not child processes. This ended up being a complete rewrite of the TabNine watchdog, and moving it into its own binary (WD-TabNine).
To accelerate our development processes, we split the system into multiple “services”. Each such service is completely decoupled from the rest of the system, and only accessible via a well defined, versioned protocol.
Splitting the system into “microservices” allows developers on the team to work on smaller discrete services that are easier to reason about, and easier to test and maintain. It also allows us to introduce certain components in languages other than Rust. While we love Rust, certain system components do not require its power and complexity.
With the current release of Tabnine, we distribute three service binaries in addition to the main Tabnine binary – TabNine-deep-local, TabNine-deep-cloud and WD-TabNine.
In the coming months, we expect additional parts of Tabnine to be delivered as separate services.
Explore recent posts
//Explore recent posts
//
3 -min read
3 -min read

5 -min read

More Announcements
//5 -min read
3 -min read
4 -min read